9 Using Wolframite to analyse cycle trips data
(ns for-developers.demo-analysis-cycling
(:require
[clojure.java.io :as io]
[clojure.string :as str]
[wolframite.api.v1 :as wl]
[wolframite.lib.helpers :as h]
[wolframite.wolfram :as w :refer :all
:exclude [* + - -> / < <= = == > >= fn
Byte Character Integer Number Short String Thread]]
[wolframite.impl.wolfram-syms.intern :as intern]
[scicloj.kindly.v4.kind :as k])
(:import (java.util.zip GZIPInputStream)))We introduce you, the motivated Clojure developer, to using the Wolfram programming language as a Clojure library. Following some brief inspiration (why on earth should you do this?), and some getting started notes, we outline a ‘real’ workflow using the example of analysing data about bike trips.
First, start & connect to a Wolfram Kernel (assuming all the common requires):
(wl/start!){:status :ok, :wolfram-version 14.2}Now, let’s play with some data! But first we will need to read them in from a CSV file. The docs tell us how to import the first ten lines of a CSV:
Import["ExampleData/financialtimeseries.csv", {"Data", 1 ;; 10}]However, how do we write the 1 ;; 10 in Wolframite?! Let’s ask!
(wl/->clj "1 ;; 10")(Span 1 10)Thus, we could write it as '(Span 1 10) (notice the important quote!), but we rather use our convenience functions:
(w/Span 1 10)(Span 1 10)Ideally, we’d take the easy path and follow the docs and use the very smart and flexible Import on our 202304_divvy_tripdata.csv.gz. Sadly, the current version of Wolfram is not very efficient at this and with our 400k rows it is unbearably slow. I assume that with the shortened, 100k row file it wouldn’t be much different. All the smartness and auto-detection costs 🤷. If we read only a few rows then it is fine (±2s for 10s - 100s of rows):
(k/table
{:row-vectors
(-> (w/Import (.getAbsolutePath (io/file "docs-buildtime-data/202304_divvy_tripdata_first100k.csv.gz"))
["Data" (w/Span 1 3)])
wl/!)})| ride_id | rideable_type | started_at | ended_at | start_station_name | start_station_id | end_station_name | end_station_id | start_lat | start_lng | end_lat | end_lng | member_casual |
| 8FE8F7D9C10E88C7 | electric_bike | |
|
|
|
|
|
41.8 | -87.6 | 41.79 | -87.6 | member |
| 34E4ED3ADF1D821B | electric_bike | |
|
|
|
|
|
41.87 | -87.65 | 41.93 | -87.68 | member |
| 5296BF07A2F77CB5 | electric_bike | |
|
|
|
|
|
41.93 | -87.66 | 41.93 | -87.66 | member |
Note: Loading the ± 400k rows file with the awesome SciCloj tooling would take ± 3.5s. How amazing is that?!
It would be nice to load the data with SciCloj / dtype.next and send it to Wolfram as data, but I haven’t yet figured out a truly efficient way to share large binary data. (I need to explore 2D heterogeneous arrays more….)
Thus we will need a more DIY and lower-level approach to getting the data in, leveraging OpenRead and ReadList. Sadly, it cannot handle a gzpipped files (as far as I know) so we need to unzip it first:
(when-not (.exists (io/file "/tmp/huge.csv"))
(let [zip (io/file "docs-buildtime-data/202304_divvy_tripdata_first100k.csv.gz")]
(with-open [zis (GZIPInputStream. (io/input-stream zip))]
(io/copy zis (io/file "/tmp/huge.csv"))))
:extracted):extractedNow we are ready to read the data in. We will store them into a Wolfram-side var so that we can work with them further.
For readability and auto-completion, we will define vars for the names of the Wolfram-side vars that we need (notice Wolfram only supports alphanumeric names):
(def csv "Wolf var - whole content" 'csv)(def rawRows "Wolf var - unparsed data rows" 'rawRows)(def rows "Wolf var - parsed data rows" 'rows)(wl/! (w/do (w/= 'f (w/OpenRead "/tmp/huge.csv"))
(w/= csv (w/ReadList 'f
w/Word
(w/-> w/WordSeparators [","])
(w/-> w/RecordSeparators ["\n" "\r\n" "\r"])
(w/-> w/NullWords true)
(w/-> w/RecordLists true)))
;; Let's return only the length instead of all the large data:
(w/Length csv)))100000We leverage the flexibility of ReadList, instructing it to read “Words” separated by , (instead of applying the normal word separating characters), thus reading individual column values. It reads them as records, separated by the given separators (which are the same as the default, shown here for clarity). I.e. each line is considered to be a record. And with RecordLists -> True we instruct it to put each record into a separate list and each row will thus become a list of values (instead of a single long list of all the column values in the whole file). Finally, we set NullWords -> True not to skip empty column values, so that all rows will have the same number of elements.)
(We could have instead used ReadList with something like (w/ReadList 'f (w/Table w/Record [13]) (w/-> 'RecordSeparators ["," "\n"])), telling it we have sequences of 13 records, where each record is separated by , (column separator) or \n (row separator). But this requires us to count the number of columns up-front.)
Let’s extract column names:
(def headers (->> (wl/! (w/Part csv 1))
(map #(str/replace % "\"" ""))))Let’s have a look at row 98,765 to verify we get the data correctly:
(k/table
{:row-vectors (map vector
headers
(wl/! (w/Part csv 98765)))})| ride_id | "0D87A4BCFFB41FA9" |
| rideable_type | "electric_bike" |
| started_at | "2023-04-21 17:39:39" |
| ended_at | "2023-04-21 18:03:34" |
| start_station_name | "Wilton Ave & Diversey Pkwy" |
| start_station_id | "TA1306000014" |
| end_station_name | |
| end_station_id | |
| start_lat | 41.932472587 |
| start_lng | -87.652724147 |
| end_lat | 41.9 |
| end_lng | -87.67 |
| member_casual | "member" |
Now, let’s make a few helpers:
(def header->idx
"Header -> column index (1-based)"
(zipmap headers (next (range))))(defn col [row-sym col-name]
(w/Part row-sym (header->idx col-name)))(defn rowvals
"Return a Wolfram fn extracting values of the named columns and returning them as a Wolf list / Clj vector"
[& col-names]
(w/fn [row] (mapv #(col row %) col-names)))Now, let’s parse strings into numbers so that we can use them in computations.
The recommended way is to use ToExpression, but it is too smart and thus slow. We will need to cheat and use the internal StringToMReal instead. I got these performance tips from SO. Let’s see how it works:
(or (= 12.34 (wl/! '(Internal/StringToMReal "12.34")))
(throw (ex-info "StringToMReal doesn't work/exist anymore?!" {})))trueLet’s make our life easier by creating a wrapper var for this function. It is somewhat of a cheat, since it isn’t a part of the public api (yet):
(def StringToMReal (intern/wolfram-fn 'Internal/StringToMReal))We can now get rid of the annoying quote, and it still works 🤞:
(wl/! (StringToMReal "12.34"))12.34Let’s store the data without the header row as rawRows (and again, ensure we do not return the whole data set):
(wl/! (w/Length (w/= rawRows (w/Drop csv 1))))99999(def loc-ks ["start_lat" "start_lng" "end_lat" "end_lng"])Now we extract and parse the columns of interest (processing all but displaying only the first 3 here):
(k/table
{:column-names ["Start latitude" "Start longitude"
"End latitude" "End longitude"]
:row-vectors
(time ; 0.6s w/ Map only, ~2s with Select as well
(wl/! (-> (w/= rows
(->> (w/Select rawRows (w/AllTrue (w/fn [v] (w/Not (w/== v "")))))
(w/Map (w/Composition
(w/Map StringToMReal)
(apply rowvals loc-ks)))))
(w/Part (w/Range 1 3)))))})| Start latitude | Start longitude | End latitude | End longitude |
|---|---|---|---|
| 41.65186780228521 | -87.53967136144637 | 41.65186780228521 | -87.53967136144637 |
| 41.803038 | -87.606615 | 41.803038 | -87.606615 |
| 41.862429738 | -87.651152372 | 41.862378 | -87.651062 |
Notice few tricks here: 1. We leverage the operator form of AllTrue so we don’t need to wrap it in a function 2. We use Composition so that we can leverage our already defined rowvals to extract the values we care about, and then to parse them.
Let’s update our helper to reflect the new columns of rows:
(defn rowvals' [& col-names]
(let [header->idx' (zipmap loc-ks (next (range)))]
(w/fn [row] (mapv #(w/Part row (header->idx' %)) col-names))))For me, it took ±0.8s to extract the 2 columns as text and 1.5s to parse them into numbers. With ToExpression it would take ±5s.
9.0.0.1 Starting positions in a map
One interesting thing to look at is how the starting positions of the trips are distributed.
In a REPL session, we could have used the following, to show the graphic in a Java Swing window:
(comment (->> rows
(w/Map (rowvals' "start_lat" "start_lng"))
w/GeoHistogram
((requiring-resolve 'wolframite.tools.graphics/show!))))but for this web page, we want to export and include the graphic as an image:
(let [file (io/file "notebooks" "start-locs.webp")]
(when-not (.exists file)
(time (wl/! (let [d (->> rows
(w/Map (rowvals' "start_lat" "start_lng"))
w/GeoHistogram)]
(w/Export (.getAbsolutePath file) d
(w/-> w/ImageSize 300)
#_(w/-> w/ImageSize w/Large))))))
(k/hiccup [:img {:src (.getPath file) #_#_:style {:width "50%" :height "50%"}}]))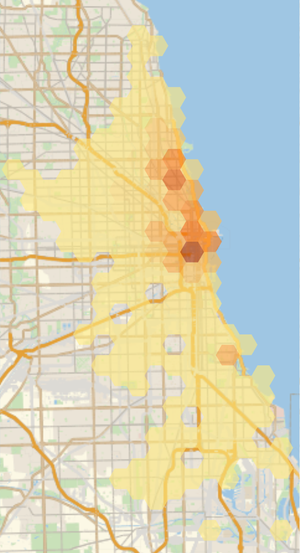
TO BE CONTINUED - featuring GeoDistance & more!